
Introducing UpScan: In the sorting room (Part II)
Last time in part I I detailed how we have set up our UpScan lab environment so that we can observe malware in as natural a setting as possible and are using the UpSight client to collect observations about behavior. This time I’m going to talk about what we do with those observations.

UpSight’s UpScan analytics builds out our digital tree of attack sentences.
We source malware samples to UpScan from public and private malware repositories that exist to share knowledge within the cyber security research community. Some of the samples are very much malicious and some of them are ‘false positives’ and are benign, afterall people have different motivations for sharing a sample. As such we can not assume that just because a sample came from a malware repository that it was in fact malicious. We instead determine this the same way we protect endpoints - by observing behavior and seeing if the sample constructs an attack sentence by its behavior that describes a malicious activity.
The purpose of UpSight analytics is to process all of the event data streaming out of the UpScan virtual containers and build “Attack Sentence” training data for our ML pipeline. Our AI model has four components: determining lexical correctness (is an event an Attack Word), sentence forming (think about a crowded room with many people talking, determining if any two words you heard are related to each other? - we call this our ‘causal mode’) determining grammatical correctness (do Attack Words go together in a sentence that way?) and finally the sentiment of the sentence (does the sentence describe an attack?). Analytics plays a part in developing each part of our AI.
Damp Squibs
The first stage is to basically determine if the sample did anything at all. As I mentioned before there can be a number of reasons including outright coding errors, missing dependencies, missing command and control networks or perhaps it's shy about being in a virtual machine. Just about 40% of samples we’ve processed so far end up in this bucket. We have some ideas about how to investigate these further in the future, but trying to keep the main thing the main thing for the moment…
Live Ones
The remaining samples are sorted into a few remaining buckets. The first one is the ‘easy case’. These are samples that clearly got down to work trying to steal credentials or encrypt documents and so on. Clustering attack sentences from this first group allows us to track attack campaigns by the general family and get an idea of the prevalence of the attack, which helps strengthen the model's ability to determine the sentiment of attack sentences.

A post-authentication credential stealer being detected by UpSight within our UpScan lab.
Everything else
This is where it gets interesting. What are left did exhibit Attack Word behaviors… but did not quite form a coherent Attack Sentence that our model was able to identify, and sorting these is really the main job of analytics.
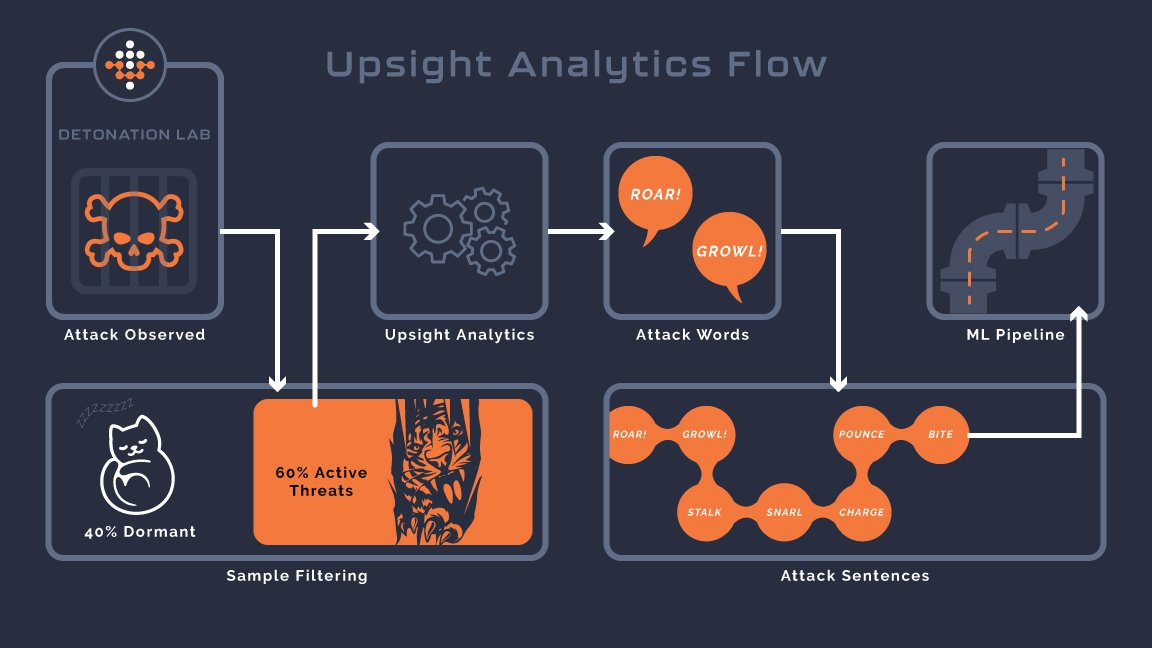
UpSight’s UpScan analytics flow finds gaps in our AI model
Sentence fragments
We can look at these further and try and identify if we ended up with two or more attack sentence ‘fragments’ that we were unable to bring together to form a complete sentence. This typically means that we missed some important causal relationship and need to do work to improve our causality model so that we are better able to form sentences in the future.
Missing words
Another bucket that we get are attack sentences that are incoherent due to missing words within them. This typically indicates that we need to do work to improve our attack word classifications. This is basically the process for learning about new words that should be added to the ‘Attack Lexicon’.
Unclear meaning
And finally we might have complete attack sentences, but our model did not pick up as having a malicious intention. This is actually the most challenging scenario and is a pretty classic problem in machine learning data science. Basically we have an attack sentence and we need to apply a label to the entire sentence of ‘attack’ or ‘not attack’. We must consider that individual samples might not be malicious at all. We can on a limited basis at this point look to other vendors (aka Virus Total) or directly dig in and make a judgment call based on our decades of experience. If the sample is a true positive, we can use it to build a better model and incorporate the newly learned lexicon, grammar and sentiment into the next generation of the model. Again we have some ideas in this area on how to automate this portion, but that remains future work.
At this point UpSight analytics has sorted our UpScan results into actionable collections that are ready to be used to create the next generation of our AI models. Next time I’m excited to share how we are working to make UpScan available as a research tool to you!